Failure Bow #1 - The AWS Lambda Goof
Posted on Sat 05 May 2018 in Posts
So this post is going to be more "storytelling" than "tutorial". I'm writing this for a couple reasons:
- it's funny
- I think it important to learn from your mistakes by reflecting back on them
- it's funny
- It shows how easy it is to accidentally spend money on AWS
- Have I mentioned the humour aspect?
Ok, really it's not that funny, but I'm laughing because it helps comfort the fact that I wasted some money due to a dumb technical goof.
So, the story: one day about a month ago, I went to https://tools.pingdom.com and ran this site through Pingdom's speed test. It gave back a bunch of recommendations around how to improve the performance of my site, one of those being to "Leverage Browser Caching" by setting a particular HTTP header on resources that don't change often (ex: images). It'll look something like:
Specifically you set the
Cache-Control header
which is used to communicate to client browsers that a resource can be cached client-side
for an extended period of time so that if a page is refreshed, that (large yet
never changing) resource doesn't have to be refetched again. Common patterns are to
set the header to a value of public, max-age=604800 to indicate 1 week (60x60x24x7==604800).
Cool, so because this site is hosted in AWS in a S3 bucket, you have to specify this header there on the resource in the bucket (unfortunately you can't set this header in Cloudfront). In the console this is easy:
- find the object in the bucket
- pick "Properties" on the object
- under "Metadata" you can add arbitrary headers including
Cache-Control
Which works, but is tedious if you have many files to update. I then spent a period of time looking into various ways to have this metadata set automatically when I push content to S3 on deploying changes to the site. This proved to be trickier than one would think, but one idea was to set this value via a Lambda. The idea:
- create a Lambda which fires when an object is put into a particular S3 bucket
- that Lambda then looks the item in the bucket
- if the name ends with
pngorjpgorjs, etc add the header as metadata
Simple right? And this is sweet in that it's a "set it and forget it" option -- once the Lambda is set, you just upload stuff as you did before and Lambda takes care of setting the header.
So I wrote up a simple Lambda, and tested it out, worked great.
And that's when things started to go sideways. You see, the Lambda would do a copy_object
on the object to set the metadata. That is, the Lambda which was triggered by a put of an
object to an S3 bucket would (as processing the object) put the object into that S3 bucket
with updated metadata.
And I think this is the point where you realize the problem. Effectively I created an infinite loop of lambda calls.
The first warning sign was later that day I got an email from AWS saying I was approaching the free tier limit for Lambda (1,000,000 calls). Given I just hooked up the Lambda that day this surprised me. The thing is though, Lambda is stupid cheap (even past 1M it's literally pennies per million or so calls). So this was mistake #2 -- not acting immediately thinking "ah, that's weird, I'll look into it later".
By the time that "later" happened and I turned off the Lambda, I had accrued around 1.1 million Lambda requests:

But that's nothing:the real problem was that each one of those lambda calls represented
a PUT to a S3 bucket.
PUT's with S3 are actually one of the more expensive operations. For the ca-central-1
region where I host my stuff, it's currently $0.0055 per 1,000 of them. This
sounds unbelievably cheap, and it is, but when you're doing about 1.1 million of
them, well, that adds up:

Queue the Iron Maiden -- 6, 6, 6, THE NUMBER OF THE BEAST!
To give some context: this site usually costs me well under $0.50 a month, the biggest portion of which is Cloudfront which clocks in around $0.24. Everything else is misc stuff: data transfer, S3 storage costs, S3 request costs, I have some old data in Glacier, etc. So to see ~$7 accrued in a day felt, well, excessive.
What really bugged me was how dumb I felt, such a silly mistake. What's kinda scary is that had I not gotten that email from AWS indicating I was close to the free tier limit, I likely wouldn't have noticed until near the end of the month, which would've turned that bill into likely well over $100.
But in the end I got a funny picture, this is the graph of my S3 bill for the month of April:
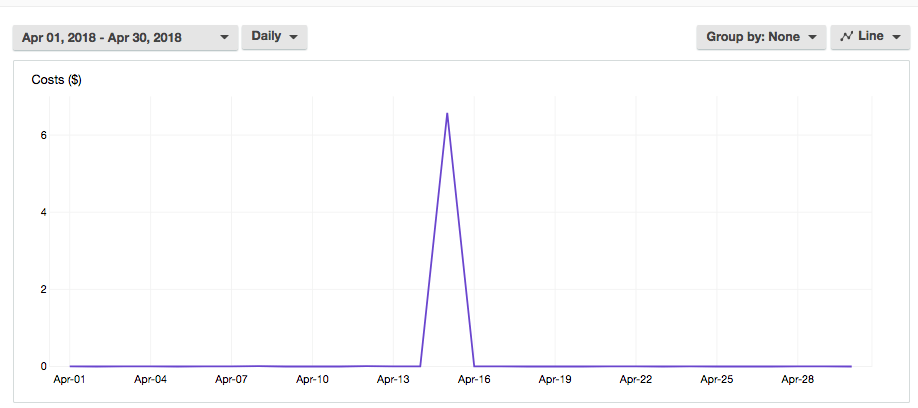
Ouch, that's a pointy point in my pride.